
Анализ популярной музыки
На Kaggle я нашла огромный архив музыкальных данных от Discogs — крупнейшего краудсорсингового каталога релизов. Меня заинтересовало, как можно визуализировать музыкальные тренды по жанрам, десятилетиям, видео и участию в группах. Для визуального оформления я вдохновлялась эстетикой Spotify Wrapped и выбрала соответствующую палитру.

Этот график показывает, как менялась популярность жанров с 1950-х годов. Я оставила только топ-5 жанров, чтобы сделать акцент на главных трендах.
Сначала я отфильтровала [masters_master_year], оставив значения только от 1950 до 2025, чтобы избавиться от аномалий. Затем округлила год до десятилетия и посчитала количество релизов по жанрам и десятилетиям:
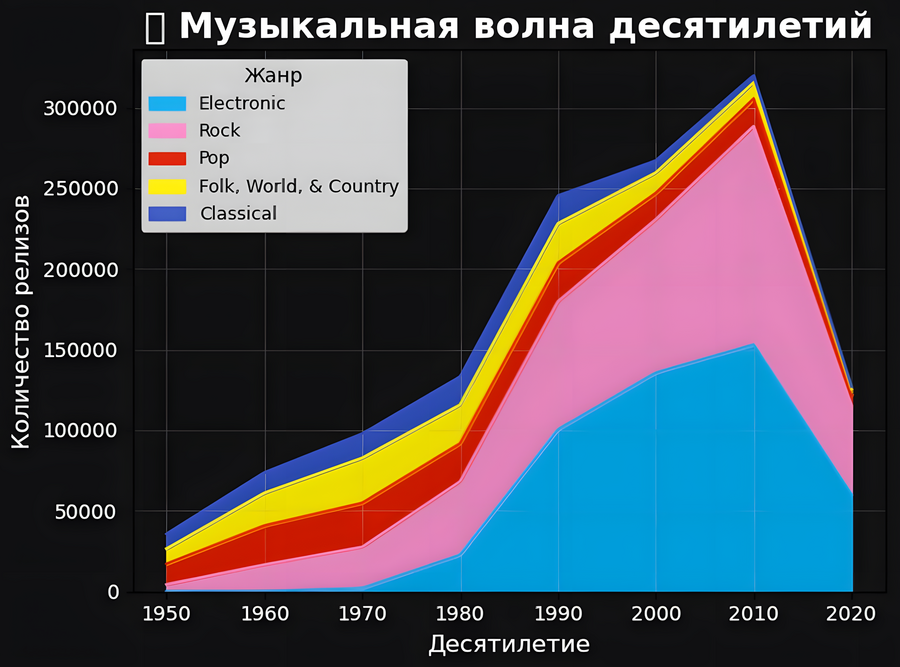
Музыкальная волна десятилетий
df = masters_df[['master_genres_genre', 'masters_master_year']].dropna () df['masters_master_year'] = pd.to_numeric (df['masters_master_year'], errors='coerce') df = df[(df['masters_master_year'] >= 1950) & (df['masters_master_year'] <= 2025)] df['decade'] = (df['masters_master_year'] // 10) * 10
Другая метрика — это средняя длительность видео в релизах. Я извлекла и усреднила длину видео по каждому жанру. Данные о длительности видео хранились как списки строк. Чтобы их обработать, я применила [ast.literal_eval], затем — конвертацию в числа и расчёт среднего:
Средняя длительность видео по жанрам
def parse_duration_list (duration_str): try: values = ast.literal_eval (duration_str) values = [int (v) for v in values if v.isdigit () and int (v) > 0] return np.mean (values) if values else np.nan except: return np.nan
Иерархический график, где центральная категория — жанры, а внешние — стили. Хорошо показывает разнообразие музыкального мира Discogs.
Чтобы построить иерархию жанр → поджанр, я изначально преобразовала колонки [master_genres_genre] и [master_styles_style] в списки. После этого создала строки-пары для графика:
Sunburst: жанр и стиль
exploded_rows = [] for _, row in df_sun.iterrows (): for genre in row['genre_list']: for style in row['style_list']: exploded_rows.append ({'Genre': genre, 'Style': style})
Я проверила, заполнено ли поле [groups_name], чтобы определить, принадлежит ли артист группе. Это дало мне метку, с которой мы построили круговую диаграмму:
Кто чаще — сольные артисты или группы
df_artists['is_group_member'] = df_artists['groups_name'].notna () & df_artists['groups_name'].astype (str).str.strip ().ne ('') group_counts = df_artists['is_group_member'].value_counts ()



